Mistral AI Releases Mistral Small 3.2: Enhanced Instruction Following, Reduced Repetition, and Stronger Function Calling for AI Integration


With the frequent release of new large language models (LLMs), there is a persistent quest to minimize repetitive errors, enhance robustness, and significantly improve user interactions. As AI models become integral to more sophisticated computational tasks, developers are consistently refining their capabilities, ensuring seamless integration within diverse, real-world scenarios.
Mistral AI has released Mistral Small 3.2 (Mistral-Small-3.2-24B-Instruct-2506), an updated version of its earlier release, Mistral-Small-3.1-24B-Instruct-2503. Although a minor release, Mistral Small 3.2 introduces fundamental upgrades that aim to enhance the model’s overall reliability and efficiency, particularly in handling complex instructions, avoiding redundant outputs, and maintaining stability under function-calling scenarios.
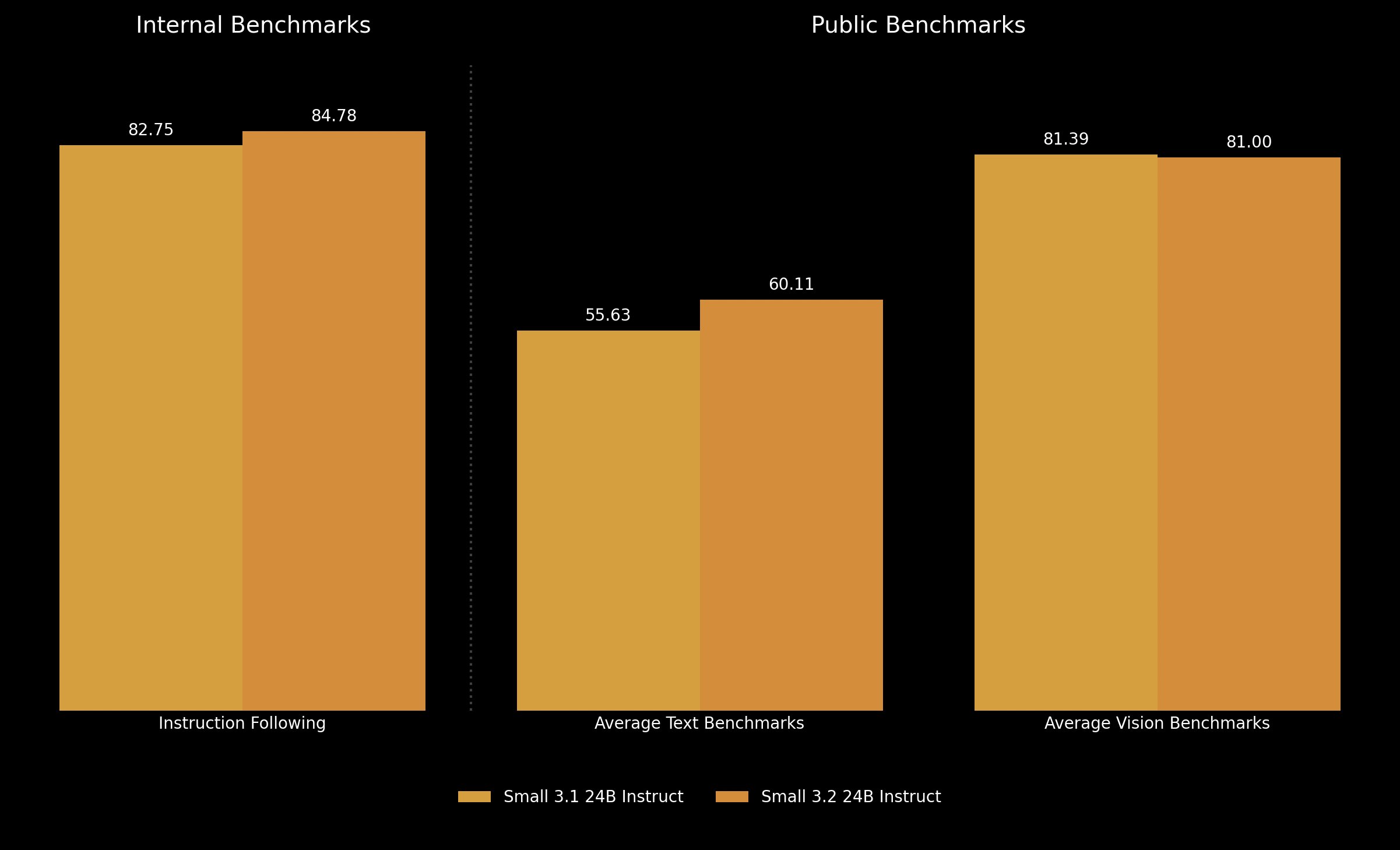
A significant enhancement in Mistral Small 3.2 is its accuracy in executing precise instructions. Successful user interaction often requires precision in executing subtle commands. Benchmark scores accurately reflect this improvement: under the Wildbench v2 instruction test, Mistral Small 3.2 achieved 65.33% accuracy, an improvement from 55.6% for its predecessor. Conversely, performance in the difficult Arena Hard v2 test was almost doubled, from 19.56% to 43.1%, which provides evidence of its improved ability to execute and grasp intricate commands precisely.
Correcting repetition errors, Mistral Small 3.2 greatly minimizes instances of infinite or repetitive output, a problem commonly faced in long conversational scenarios. Internal evaluations show that Small 3.2 effectively cuts instances of infinite generation errors by half, from 2.11% in Small 3.1 to 1.29%. This complete reduction directly increases the model’s usability and dependability in extended interactions. The new model also demonstrates greater capability to call functions, making it ideal for automation tasks. Also, improved robustness in the function calling template translates to more stable and dependable interactions.
STEM-related benchmark improvement further demonstrates Small 3.2’s aptitude. For example, the HumanEval Plus Pass@5 code test had its accuracy increase from 88.99% in Small 3.1 to a whopping 92.90%. Also, MMLU Pro test results increased from 66.76% to 69.06%, and GPQA Diamond ratings improved slightly from 45.96% to 46.13%, showing general competence in scientific and technical uses.
Vision-based performance outcomes were inconsistent, with certain optimizations being selectively applied. ChartQA accuracy improved from 86.24% to 87.4%, and DocVQA marginally enhanced from 94.08% to 94.86%. In contrast, some tests, such as MMMU and Mathvista, experienced slight dips, indicating specific trade-offs encountered during the optimization process.
The key updates in Mistral Small 3.2 over Small 3.1 include:
- Enhanced precision in instruction-following, with Wildbench v2 accuracy rising from 55.6% to 65.33%.
- Reduced repetition errors, halving infinite generation instances from 2.11% to 1.29%.
- Improved robustness in function calling templates, ensuring more stable integrations.
- Notable increases in STEM-related performance, particularly in HumanEval Plus Pass@5 (92.90%) and MMLU Pro (69.06%).
In conclusion, Mistral Small 3.2 offers targeted and practical enhancements over its predecessor, providing users with greater accuracy, reduced redundancy, and improved integration capabilities. These advancements help position it as a reliable choice for complex AI-driven tasks across diverse application areas.
Check out the Model Card on Hugging Face. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.

